Our journey with Docker and Terraform on the Google cloud platform
As an engineering team, we always operated with a modest infrastructure. We depended more on best practices to serve the business. Still, as we grew and projected the future, we understood the need to build site reliability engineering expertise to deliver reliable services.
Lately, we have started building software for Grain’s Thailand market. It was relatively straightforward on the core business software, which allowed us to explore the infrastructure side of things. Starting fresh is always a unique opportunity to realize all the exciting things you’ve been researching, which are infeasible with legacy systems. Building software and especially the infrastructure for this new market felt like the one to us.
We decided to adopt the relevant technologies and build for this new market with a more rigorous commitment. We had a good thought and goal; we decided to figure out an infrastructure that is simple enough to maintain without compromising security and scalability.
Here’s how and what we did with it.
Few more details before we start — we are a technology company based in Singapore working in the F&B industry. We run our backend on Ruby on Rails, and the front end includes a mix of Vue, React and React Native. We are entirely on the Google cloud platform using a range of computing and storage products.
I’ll be essentially running you through this infrastructure image below and talk about a few difficulties we encountered along the way.
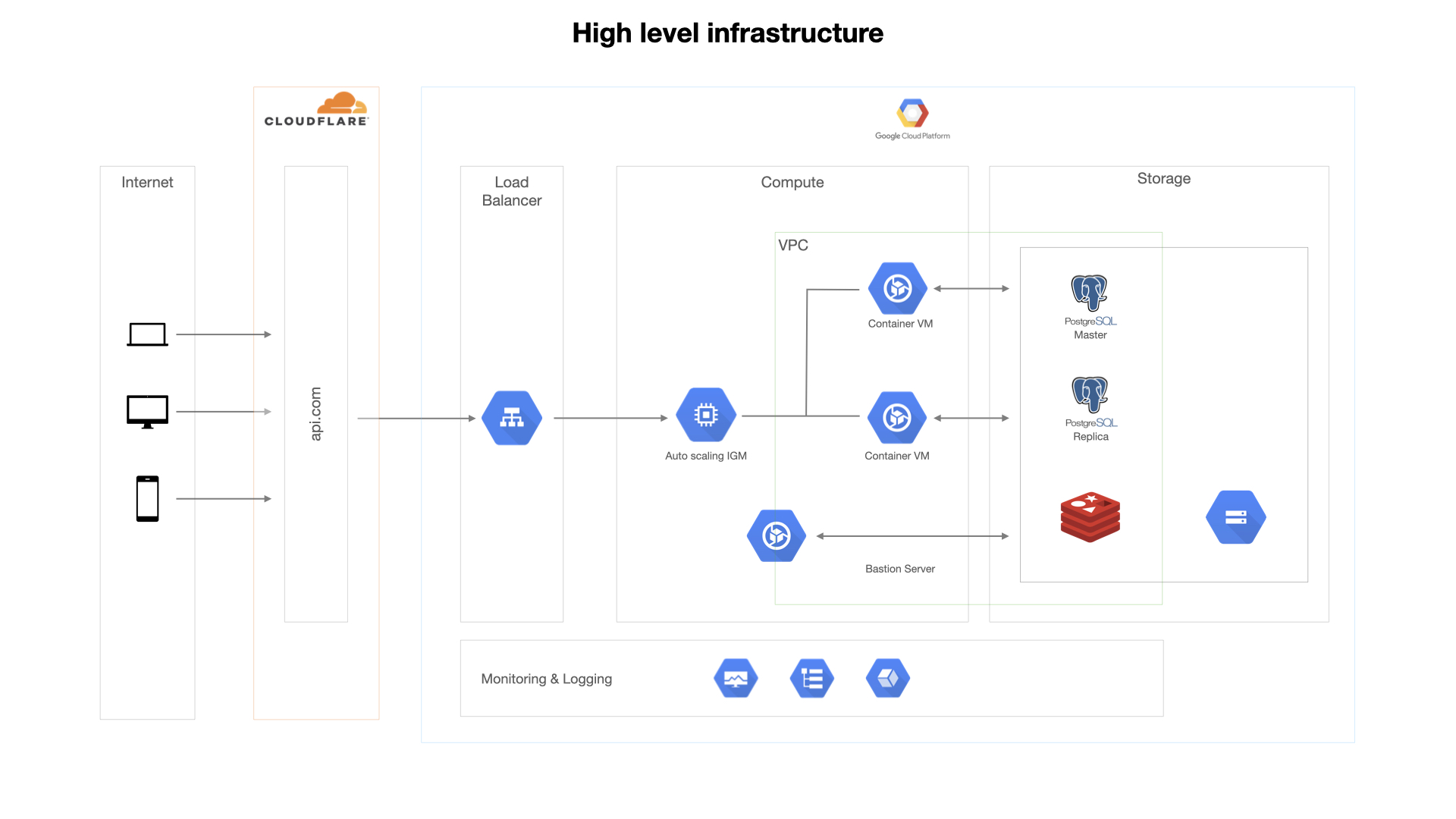
Containers
By now, we all have endured the benefits of containerizing the applications. I won’t repeat it and talk more about implementation.
Cloud build and Container Registry
Instead of using the actual docker daemon, we opted for google/cloud-sdk to get the job done as it suited well with the platform. Our CI/CD pipelines are on CircleCI.
We used cloud build within the docker to build our images of our dockerized Ruby on Rails apps and publish them to the container registry. Images are stored in a storage bucket located in a region of our choice.
Under the hood, cloud build uses GoogleContainerTools/kaniko to build images. One of the gotchas was publishing an image with multiple tags1. We wanted to have multiple tags and found some difficulties in doing so, and we solved it by using a configuration file; it’s a simple YAML file that allows us to do a bit more.2
Thanks to Rails’ secrets encryption feature, we didn’t have much difficulty managing secrets in our applications.
Container-Optimized VMs
Instead of having a custom setup on a distro, we opted for container optimized VMs; these are lightweight VMs running customized OS preinstalled with docker and other monitoring tools. Easy to manage and maintain.
There was no easy way to map VM’s ports to container ports3. We had to write an IP table rule as part of the startup script to achieve it.
All the VMs are part of a managed instance group attached as a backend service to a load balancer with autoscaler, configured for our needs. All these resources, including the storage, are running in a custom VPC with fine-grained permissions
We perform a rolling update action on the managed instance group to substitute existing VMs with new code with at least one active VMs to achieve zero downtime while continuously deploying code.4
Infrastructure as code
Terraform
I must say, moving to Terraform one of the best decisions we have made. We’ve always maintained all our staging and production resources in a single project, and it got difficult to manage them over time. Thanks to Terraform, it helped us solve this problem; of course, it’s on top of all the benefits IaC tools provide.
We now manage two different environments with Terraform; both these states are backed by google storage buckets of respective projects. We use separate variables and credentials files depending on the environment to provision the resources. We are planning to use workspaces5 to improve the process further.
We used terraform-google-modules/terraform-google-container-vm to provision the VMs and developed custom modules for the rest of the resources. Life cycle blocks6 came in pretty handy to circumvent panic when we were experimenting with the infrastructure.
Monitoring
Monitoring is a necessary part of building reliable systems, and the right set of tools makes it easier for us to understand the system’s status. Google’s monitoring and logging system seemed like a good fit for us, mostly because of its more straightforward configuration for all the services.
We have health checks in place and have a plan to add the pager rules to improve the whole recovery process shortly.
We additionally started exploring tools like Grafana. Cloud Run7 came in beneficial here; we run these pilot services on serverless infrastructure to lower costs and not incur any additional maintenance.
It took us about four weeks to get all of this into some shape. I won’t say it was challenging, but we had fewer obstacles than we thought would arise along the process.
Adopting these technologies has set us on a path to achieve the goals we have developed. Thanks to reliable tools, we are now more confident to solve the problems.
We’re not done yet; we’ll be investing more time improving it, keeping an eye on the new technologies in this space, and exploring it further to build even more reliable systems. It’s exciting.
Thanks for reading.
I led most of the development efforts and took the liberty to share them with you all. Please feel free to reach out to me (email) if you have any questions and ideas, I’ll be happy to take your feedback, help, and discuss it further.
Notes
-
https://github.com/GoogleContainerTools/kaniko/issues/217 ↩
-
https://cloud.google.com/cloud-build/docs/configuring-builds/create-basic-configuration ↩
-
https://cloud.google.com/compute/docs/containers/deploying-containers#limitations ↩
-
https://cloud.google.com/compute/docs/instance-groups/rolling-out-updates-to-managed-instance-groups ↩
-
https://www.terraform.io/docs/state/workspaces.html ↩
-
https://www.terraform.io/docs/configuration/meta-arguments/lifecycle.html ↩
-
https://cloud.google.com/run/ ↩